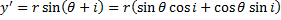I'd like to make a brief mathematical investigation into the concept of a wind chill factor and how one particular scheme common in popular culture (and even affecting some in industry) does not relate well to modelling of a building envelope. Wind chill is the temperature which a human being perceives accounting for the effects of wind and temperature together. The preceding sentence is awkward because it is trying to say too much at once, so let me try again:
A wind chill index (expressed in units equivalent(ish) to temperature measurements) is answering a question: What temperature T
WC (with wind speed = 0) will be perceived
by a human being as equivalent to temperature T
actual (with wind speed = V
actual)? (We are talking here more particularly about the exposed skin of a human being. Also, it isn't purely a matter of perception.)
Human beings, not buildings. Consider the following differences:
- buildings (in cold climates) have a much lower surface temperature than humans
- the amount (and temperature) of moisture on their surfaces is generally different and has a different internal transport mechanism (brick has basically no moisture and that moisture is already cold, human skin normally has moisture—perspiration—which evaporates more rapidly in windy conditions than calm conditions causing heat loss, because evaporation requires energy)
- unlike human beings, buildings do not have psychological comfort issues affecting their perception of temperature (and, admittedly, cannot reasonably be considered to perceive anything)
The equation used today for wind chill index has some theoretical basis but in the end is empirically derived. That means they did experiments and found something that "works". It is a very pragmatic way to deal with complex issues, especially ones that include psychological/cognitive components. (I'm not "disrespecting" empirical equations, they're useful.)
So, where do I start? I would hard pressed with my current knowledge/understanding to deal with the evaporative cooling effects on human skin as compared with buildings, though such investigation might be meritorious. I will not attempt to compare the psychology of buildings with that of humans—I hope you understand. I will however seek to show how the concept of an "equivalent temperature in the absence of wind" yields different results depending on the surface temperature of the material in question. As such, although we will not compare human skin with face brick, we will compare warm Surface X with cool Surface X.
Convective Heat Transfer
The convective heat transfer equation is simple enough:
q = hc AS (TS – Tair)
where q is the heat energy (per unit time), hc is the heat transfer coefficient, AS is the surface area, TS is the temperature of the surface and Tair is the ambient air temperature.
The heat transfer coefficient varies with wind speed. Suppose we want to find an air temperature TWC (no wind, hNW) which causes the same rate of heat loss as Tactual (wind speed = Wactual, hactual). In that case, we need to relate:
h
NW A
S (T
S – T
WC) = q = h
actual A
S (T
S – T
actual),
which simplifies to
T
WC = T
S – (h
actual / h
NW)(T
S – T
actual).
A Little Problem
This leaves me with a problem. I want to have some type of reasonable value for the convective heat transfer coefficient ratio (h
actual / h
NW). How do I get that? I will engage in a little pragmatism and pretend that the wind chill equation will still give me a way to get an (h
actual / h
NW) ratio. This is perhaps a dubious step, but may suffice for illustrative purposes. From the wind chill equation we get a 15 mph wind at -31°F being equivalent to no wind at -59°F. Here's what we get for the ratio for human skin (which I have to use since that's what the wind chill equation is based on):
(h
actual / h
NW) = (T
S – T
WC) / (T
S – T
actual)
= (88 – (-59)) / (88 – (-31))
= 1.235
(I've used 88°F for human skin, but that temperature will be different depending on the ambient temperature. Oh, well, what do you do when you live in a shoe?)
Theoretically, the convective heat transfer coefficient is largely independent of temperature and area, but it will change based on the interaction of the fluid and the surface which will include things like geometry, orientation, surface roughness, moisture, etc. Unfortunately, temperature differences may affect the actual coefficient. They will affect the result if you consider radiation losses as well, since radiation transport is proportional to absolute temperature to the fourth power.
Wind Chill Effect on Surfaces at Different Temperatures Than Human Skin?
So, let's consider a surface which is maintained at a temperature of 10°F and is surrounded by an ambient temperature of -31°F and the wind speed is 15 mph. (This is not the temperature in the boundary layer. The point of the convective heat transfer equation is to deal with this phenomenon in a simplified way—essentially to circumvent it.) So, what's my "equivalent temperature in the absence of wind"?
T
WC = T
S – (h
actual / h
NW)(T
S – T
actual)
= 10 – 1.235 (10 – (-31))
= -40.6 °F
So, the rate of heat loss from Surface X under the actual conditions is the same as the rate of heat loss for Surface X with no wind and a temperature of -40.6°F.
We obtained a different value than we did for the wind chill index applicable to human skin. The reason is straightforward: the rate of heat loss is proportional to the difference between the ambient air temperature and the surface temperature. Now, if it is -31°F outside, what temperature is the outside surface of a building? Perhaps -21°F? This makes quite a difference:
T
WC = T
S – (h
actual / h
NW)(T
S – T
actual)
= -21 – 1.235 (-21 – (-31))
= -33.4 °F
So the effect is not zero, but it isn't much to talk about. If my h ratio is actually much higher, we will get a greater difference.
Considerations on Building Outside Surface Temperatures
The thickness and properties of the building envelope materials may change the relationship between ambient air temperature and surface temperature. Such changes will change the rate of heat loss in proportion to the temperature difference. Is there a higher difference at glazing surfaces than concrete surfaces?
There's also a sticky point regarding solar heat gains. Such gains on the surface will increase the rate of heat loss
at the surface. But watch out! This is mainly behaviour occurring at the surface. We're dealing with a cold climate situation. Radiant heat from the sun heats up the surface only to be removed by increased rates of convection and radiation loss. This does not help us analyze the heat losses from the interior of the building! Plain "horse sense" tells me that adding thermal energy to the exterior does not cause a net increase to the rate of heat loss from the building interior. At worst, the increased rate of convective (and radiation) loss will remove all of the radiant energy added. To deal thoroughly with this issue, we would either need to model both together (allowing them to interact numerically with each other—for transient analysis) or use a "net direct solar gain" approach that deals with the interaction of convection and radiation (gains and losses) at the surface in an integrated way. The obvious outcome is that the rate of heat loss from the interior is reduced, but determining how much could be fun times.
Note that in warm climate conditions (cooling conditions), heat on the outside surface migrates toward the interior and we must therefore consider it. It is no longer starting to go in only to double back* (as it were), but actually conducting through the envelope and so directly affecting interior conditions. (*Analogical language enjoys talking about physics.)
CAUTION: This is NOT a Final Answer
In closing, this article is
not trying to present the final answer to this problem. Rather I am attempting to expose the fallacy that the wind chill index (and corresponding formula) can be naively applied to energy modelling problems in building science. Furthermore, my criticism is not directed against nor does it address considerations of the effects of wind on air leakage analysis.
Note that ASHRAE Fundamentals chapter 26 (2009) gives effective R-values which can be used. The point of these values is to bypass all of the stuff I'm writing about in this article and account for convection and radiation losses at the surface under a 15 mph wind design condition. You don't actually need all that wind chill stuff—chapter 26 R-values already give a reasonable estimate of the wind effects, i.e., R-0.17 at 15 mph on the exterior instead of R-0.68 on the interior for still air at a wall.